from bioMONAI.data import *
from bioMONAI.transforms import *
from bioMONAI.core import *
from bioMONAI.core import Path, set_determinism
from bioMONAI.data import *
from bioMONAI.losses import CrossEntropyLossFlat
from bioMONAI.metrics import *
from bioMONAI.datasets import download_file
from fastai.vision.all import accuracy, OptimWrapper
from monai.transforms import *
from torch.optim import Adam
import os
import pandas as pdMultispectral Classification
Tutorial multispectral classification
Setup imports
import warnings
warnings.filterwarnings("ignore")device = get_device()
print(device)cudaset_determinism(0)Download dataset
In the next cell, we will download a subset of the RXRX1 dataset from the MONAI repository. This dataset contains multispectral images that we will use for our classification task. The download_file function is used to download and extract the dataset to a specified directory.
- The dataset URL is specified, and a hash is provided to ensure data integrity.
- The
extractparameter is set toTrueto automatically extract the downloaded zip file. - The
extract_dirparameter is left empty, meaning the contents will be extracted to the specified directory.
- You can change the
urlvariable to point to a different dataset if needed.- Modify the
extract_dirparameter to specify a different extraction directory.- Ensure that the
hashvalue matches the dataset you are downloading to avoid data corruption issues.
# Define the base URL for the dataset
url = "https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/rxrx1_subset_monai.zip"
download_file(url, "../_data", extract=True, hash='e80db433db641bb390ade991b81f98814a26c7de30e0da6f20e8abddf7a84538', extract_dir='')The file has been downloaded and saved to: /home/bm/Documents/bioMONAI/nbs/_dataPrepare Image Paths and Update Metadata
In the next cell, we will prepare the image paths for each channel and update the metadata CSV file with these paths. This step is crucial for organizing the dataset and ensuring that each image is correctly associated with its corresponding metadata.
- We will read the metadata CSV file and extract the site IDs.
- For each site ID, we will generate the paths for the six channels of images.
- These paths will be stored in a dictionary and added as new columns to the metadata CSV file.
- A new CSV file will be created to avoid overwriting the original metadata file.
- You can modify the
data_folderandcsv_filevariables to point to a different dataset or metadata file.- If your dataset contains a different number of channels, adjust the range in the
channel_listgeneration accordingly.- Ensure that the directory structure and file naming conventions match those expected by the code.
data_folder = '../_data/rxrx1_subset_monai/'
csv_file = os.path.join(data_folder, 'metadata.csv')
df = pd.read_csv(csv_file)
# Create label mapping from cell_type
class_map = {c: idx for idx, c in enumerate(df['cell_type'].unique())}
# Build datalist with channels + label
datalist = []
for idx, row in df.iterrows():
item = {}
# build file paths for 6 channels
for c in range(1, 7):
subpath = os.path.join("images", row.experiment, f"Plate{row.plate}")
fn = f"{row.well}_s{row.site}_w{c}.png"
item[f"channel {c}"] = os.path.join(data_folder, subpath, fn)
# add label
item["label"] = class_map[row.cell_type]
datalist.append(item)
# Let's create a new csv file to avoid overwriting the original one, and add the image paths to it in new columns
datalist_df = pd.DataFrame(datalist)
new_csv_file = data_folder + 'metadata_updated.csv'
add_columns_to_csv(csv_file, datalist_df, new_csv_file)Columns ['channel 1', 'channel 2', 'channel 3', 'channel 4', 'channel 5', 'channel 6', 'label'] added successfully. Updated file saved to '../_data/rxrx1_subset_monai/metadata_updated.csv'Split Dataset into Train, Validation, and Test Sets
In the next cell, we will split the updated metadata CSV file into training, validation, and test sets. This step is essential for training and evaluating our classification model. The split_dataframe function is used to perform the split based on the specified fractions.
- The
train_fractionparameter determines the proportion of the dataset to be used for training. - The
valid_fractionparameter determines the proportion of the dataset to be used for validation. - The
split_columnparameter specifies the column to be used for splitting the dataset. Using this parameter is alternative to ‘train_fraction’ and ‘valid_fraction’ parameters. - The
add_is_validparameter adds a column to indicate whether a sample belongs to the validation set. - The
train_path,test_path, andvalid_pathparameters specify the file paths for the resulting CSV files. - The
data_save_pathparameter specifies the directory where the CSV files will be saved.
- You can adjust the
train_fractionandvalid_fractionparameters to change the proportions of the splits.- Modify the
split_columnparameter if you want to use a different column for splitting.- Ensure that the
data_save_pathdirectory exists and has write permissions.
# Split data based on 'split_column' values in csv file
split_dataframe(new_csv_file,
split_column='dataset',
add_is_valid=True,
train_path="train.csv",
test_path="test.csv",
valid_fraction=0.1,
shuffle=False,
data_save_path=data_folder
)Using predefined dataset split
'is_valid' column added to train dataframe for validation samples.
Datasets saved to %s ../_data/rxrx1_subset_monai/( original_row_index site_id well_id cell_type dataset \
0 45589 HEPG2-01_3_C15_2 HEPG2-01_3_C15 HEPG2 train
1 59951 HEPG2-07_2_H02_2 HEPG2-07_2_H02 HEPG2 train
2 48708 HEPG2-02_4_D13_1 HEPG2-02_4_D13 HEPG2 train
3 46896 HEPG2-02_1_E09_1 HEPG2-02_1_E09 HEPG2 train
4 60402 HEPG2-07_3_D09_1 HEPG2-07_3_D09 HEPG2 train
.. ... ... ... ... ...
995 123921 U2OS-03_2_G21_2 U2OS-03_2_G21 U2OS train
996 121453 U2OS-02_2_G19_2 U2OS-02_2_G19 U2OS train
997 119034 U2OS-01_2_H20_1 U2OS-01_2_H20 U2OS train
998 118168 U2OS-01_1_C05_1 U2OS-01_1_C05 U2OS train
999 123966 U2OS-03_2_H22_1 U2OS-03_2_H22 U2OS train
experiment plate well site well_type sirna sirna_id \
0 HEPG2-01 3 C15 2 positive_control s15652 1114
1 HEPG2-07 2 H02 2 treatment s195435 683
2 HEPG2-02 4 D13 1 treatment s20197 85
3 HEPG2-02 1 E09 1 treatment s27069 313
4 HEPG2-07 3 D09 1 treatment s18250 405
.. ... ... ... ... ... ... ...
995 U2OS-03 2 G21 2 treatment s37346 1046
996 U2OS-02 2 G19 2 treatment s38759 164
997 U2OS-01 2 H20 1 treatment s21714 785
998 U2OS-01 1 C05 1 treatment s19455 999
999 U2OS-03 2 H22 1 positive_control s502431 1133
channel 1 \
0 ../_data/rxrx1_subset_monai/images/HEPG2-01/Plate3/C15_s2_w1.png
1 ../_data/rxrx1_subset_monai/images/HEPG2-07/Plate2/H02_s2_w1.png
2 ../_data/rxrx1_subset_monai/images/HEPG2-02/Plate4/D13_s1_w1.png
3 ../_data/rxrx1_subset_monai/images/HEPG2-02/Plate1/E09_s1_w1.png
4 ../_data/rxrx1_subset_monai/images/HEPG2-07/Plate3/D09_s1_w1.png
.. ...
995 ../_data/rxrx1_subset_monai/images/U2OS-03/Plate2/G21_s2_w1.png
996 ../_data/rxrx1_subset_monai/images/U2OS-02/Plate2/G19_s2_w1.png
997 ../_data/rxrx1_subset_monai/images/U2OS-01/Plate2/H20_s1_w1.png
998 ../_data/rxrx1_subset_monai/images/U2OS-01/Plate1/C05_s1_w1.png
999 ../_data/rxrx1_subset_monai/images/U2OS-03/Plate2/H22_s1_w1.png
channel 2 \
0 ../_data/rxrx1_subset_monai/images/HEPG2-01/Plate3/C15_s2_w2.png
1 ../_data/rxrx1_subset_monai/images/HEPG2-07/Plate2/H02_s2_w2.png
2 ../_data/rxrx1_subset_monai/images/HEPG2-02/Plate4/D13_s1_w2.png
3 ../_data/rxrx1_subset_monai/images/HEPG2-02/Plate1/E09_s1_w2.png
4 ../_data/rxrx1_subset_monai/images/HEPG2-07/Plate3/D09_s1_w2.png
.. ...
995 ../_data/rxrx1_subset_monai/images/U2OS-03/Plate2/G21_s2_w2.png
996 ../_data/rxrx1_subset_monai/images/U2OS-02/Plate2/G19_s2_w2.png
997 ../_data/rxrx1_subset_monai/images/U2OS-01/Plate2/H20_s1_w2.png
998 ../_data/rxrx1_subset_monai/images/U2OS-01/Plate1/C05_s1_w2.png
999 ../_data/rxrx1_subset_monai/images/U2OS-03/Plate2/H22_s1_w2.png
channel 3 \
0 ../_data/rxrx1_subset_monai/images/HEPG2-01/Plate3/C15_s2_w3.png
1 ../_data/rxrx1_subset_monai/images/HEPG2-07/Plate2/H02_s2_w3.png
2 ../_data/rxrx1_subset_monai/images/HEPG2-02/Plate4/D13_s1_w3.png
3 ../_data/rxrx1_subset_monai/images/HEPG2-02/Plate1/E09_s1_w3.png
4 ../_data/rxrx1_subset_monai/images/HEPG2-07/Plate3/D09_s1_w3.png
.. ...
995 ../_data/rxrx1_subset_monai/images/U2OS-03/Plate2/G21_s2_w3.png
996 ../_data/rxrx1_subset_monai/images/U2OS-02/Plate2/G19_s2_w3.png
997 ../_data/rxrx1_subset_monai/images/U2OS-01/Plate2/H20_s1_w3.png
998 ../_data/rxrx1_subset_monai/images/U2OS-01/Plate1/C05_s1_w3.png
999 ../_data/rxrx1_subset_monai/images/U2OS-03/Plate2/H22_s1_w3.png
channel 4 \
0 ../_data/rxrx1_subset_monai/images/HEPG2-01/Plate3/C15_s2_w4.png
1 ../_data/rxrx1_subset_monai/images/HEPG2-07/Plate2/H02_s2_w4.png
2 ../_data/rxrx1_subset_monai/images/HEPG2-02/Plate4/D13_s1_w4.png
3 ../_data/rxrx1_subset_monai/images/HEPG2-02/Plate1/E09_s1_w4.png
4 ../_data/rxrx1_subset_monai/images/HEPG2-07/Plate3/D09_s1_w4.png
.. ...
995 ../_data/rxrx1_subset_monai/images/U2OS-03/Plate2/G21_s2_w4.png
996 ../_data/rxrx1_subset_monai/images/U2OS-02/Plate2/G19_s2_w4.png
997 ../_data/rxrx1_subset_monai/images/U2OS-01/Plate2/H20_s1_w4.png
998 ../_data/rxrx1_subset_monai/images/U2OS-01/Plate1/C05_s1_w4.png
999 ../_data/rxrx1_subset_monai/images/U2OS-03/Plate2/H22_s1_w4.png
channel 5 \
0 ../_data/rxrx1_subset_monai/images/HEPG2-01/Plate3/C15_s2_w5.png
1 ../_data/rxrx1_subset_monai/images/HEPG2-07/Plate2/H02_s2_w5.png
2 ../_data/rxrx1_subset_monai/images/HEPG2-02/Plate4/D13_s1_w5.png
3 ../_data/rxrx1_subset_monai/images/HEPG2-02/Plate1/E09_s1_w5.png
4 ../_data/rxrx1_subset_monai/images/HEPG2-07/Plate3/D09_s1_w5.png
.. ...
995 ../_data/rxrx1_subset_monai/images/U2OS-03/Plate2/G21_s2_w5.png
996 ../_data/rxrx1_subset_monai/images/U2OS-02/Plate2/G19_s2_w5.png
997 ../_data/rxrx1_subset_monai/images/U2OS-01/Plate2/H20_s1_w5.png
998 ../_data/rxrx1_subset_monai/images/U2OS-01/Plate1/C05_s1_w5.png
999 ../_data/rxrx1_subset_monai/images/U2OS-03/Plate2/H22_s1_w5.png
channel 6 label \
0 ../_data/rxrx1_subset_monai/images/HEPG2-01/Plate3/C15_s2_w6.png 0
1 ../_data/rxrx1_subset_monai/images/HEPG2-07/Plate2/H02_s2_w6.png 0
2 ../_data/rxrx1_subset_monai/images/HEPG2-02/Plate4/D13_s1_w6.png 0
3 ../_data/rxrx1_subset_monai/images/HEPG2-02/Plate1/E09_s1_w6.png 0
4 ../_data/rxrx1_subset_monai/images/HEPG2-07/Plate3/D09_s1_w6.png 0
.. ... ...
995 ../_data/rxrx1_subset_monai/images/U2OS-03/Plate2/G21_s2_w6.png 3
996 ../_data/rxrx1_subset_monai/images/U2OS-02/Plate2/G19_s2_w6.png 3
997 ../_data/rxrx1_subset_monai/images/U2OS-01/Plate2/H20_s1_w6.png 3
998 ../_data/rxrx1_subset_monai/images/U2OS-01/Plate1/C05_s1_w6.png 3
999 ../_data/rxrx1_subset_monai/images/U2OS-03/Plate2/H22_s1_w6.png 3
is_valid
0 0
1 1
2 0
3 0
4 0
.. ...
995 0
996 1
997 0
998 0
999 0
[1000 rows x 20 columns],
original_row_index site_id well_id cell_type dataset \
1000 8483 HEPG2-11_2_L21_2 HEPG2-11_2_L21 HEPG2 test
1001 4658 HEPG2-09_4_I22_1 HEPG2-09_4_I22 HEPG2 test
1002 6863 HEPG2-10_4_D02_2 HEPG2-10_4_D02 HEPG2 test
1003 578 HEPG2-08_1_O05_1 HEPG2-08_1_O05 HEPG2 test
1004 9121 HEPG2-11_3_M10_2 HEPG2-11_3_M10 HEPG2 test
... ... ... ... ... ...
1195 42150 U2OS-05_1_I03_1 U2OS-05_1_I03 U2OS test
1196 43423 U2OS-05_3_J08_2 U2OS-05_3_J08 U2OS test
1197 40260 U2OS-04_2_G23_1 U2OS-04_2_G23 U2OS test
1198 40225 U2OS-04_2_G05_2 U2OS-04_2_G05 U2OS test
1199 42214 U2OS-05_1_J13_1 U2OS-05_1_J13 U2OS test
experiment plate well site well_type sirna sirna_id \
1000 HEPG2-11 2 L21 2 treatment s38490 232
1001 HEPG2-09 4 I22 1 treatment s36698 923
1002 HEPG2-10 4 D02 2 treatment s20919 139
1003 HEPG2-08 1 O05 1 treatment s21433 531
1004 HEPG2-11 3 M10 2 treatment s19088 546
... ... ... ... ... ... ... ...
1195 U2OS-05 1 I03 1 treatment s20132 850
1196 U2OS-05 3 J08 2 treatment s38090 43
1197 U2OS-04 2 G23 1 treatment s18019 940
1198 U2OS-04 2 G05 2 treatment s18863 151
1199 U2OS-05 1 J13 1 treatment s21662 596
channel 1 \
1000 ../_data/rxrx1_subset_monai/images/HEPG2-11/Plate2/L21_s2_w1.png
1001 ../_data/rxrx1_subset_monai/images/HEPG2-09/Plate4/I22_s1_w1.png
1002 ../_data/rxrx1_subset_monai/images/HEPG2-10/Plate4/D02_s2_w1.png
1003 ../_data/rxrx1_subset_monai/images/HEPG2-08/Plate1/O05_s1_w1.png
1004 ../_data/rxrx1_subset_monai/images/HEPG2-11/Plate3/M10_s2_w1.png
... ...
1195 ../_data/rxrx1_subset_monai/images/U2OS-05/Plate1/I03_s1_w1.png
1196 ../_data/rxrx1_subset_monai/images/U2OS-05/Plate3/J08_s2_w1.png
1197 ../_data/rxrx1_subset_monai/images/U2OS-04/Plate2/G23_s1_w1.png
1198 ../_data/rxrx1_subset_monai/images/U2OS-04/Plate2/G05_s2_w1.png
1199 ../_data/rxrx1_subset_monai/images/U2OS-05/Plate1/J13_s1_w1.png
channel 2 \
1000 ../_data/rxrx1_subset_monai/images/HEPG2-11/Plate2/L21_s2_w2.png
1001 ../_data/rxrx1_subset_monai/images/HEPG2-09/Plate4/I22_s1_w2.png
1002 ../_data/rxrx1_subset_monai/images/HEPG2-10/Plate4/D02_s2_w2.png
1003 ../_data/rxrx1_subset_monai/images/HEPG2-08/Plate1/O05_s1_w2.png
1004 ../_data/rxrx1_subset_monai/images/HEPG2-11/Plate3/M10_s2_w2.png
... ...
1195 ../_data/rxrx1_subset_monai/images/U2OS-05/Plate1/I03_s1_w2.png
1196 ../_data/rxrx1_subset_monai/images/U2OS-05/Plate3/J08_s2_w2.png
1197 ../_data/rxrx1_subset_monai/images/U2OS-04/Plate2/G23_s1_w2.png
1198 ../_data/rxrx1_subset_monai/images/U2OS-04/Plate2/G05_s2_w2.png
1199 ../_data/rxrx1_subset_monai/images/U2OS-05/Plate1/J13_s1_w2.png
channel 3 \
1000 ../_data/rxrx1_subset_monai/images/HEPG2-11/Plate2/L21_s2_w3.png
1001 ../_data/rxrx1_subset_monai/images/HEPG2-09/Plate4/I22_s1_w3.png
1002 ../_data/rxrx1_subset_monai/images/HEPG2-10/Plate4/D02_s2_w3.png
1003 ../_data/rxrx1_subset_monai/images/HEPG2-08/Plate1/O05_s1_w3.png
1004 ../_data/rxrx1_subset_monai/images/HEPG2-11/Plate3/M10_s2_w3.png
... ...
1195 ../_data/rxrx1_subset_monai/images/U2OS-05/Plate1/I03_s1_w3.png
1196 ../_data/rxrx1_subset_monai/images/U2OS-05/Plate3/J08_s2_w3.png
1197 ../_data/rxrx1_subset_monai/images/U2OS-04/Plate2/G23_s1_w3.png
1198 ../_data/rxrx1_subset_monai/images/U2OS-04/Plate2/G05_s2_w3.png
1199 ../_data/rxrx1_subset_monai/images/U2OS-05/Plate1/J13_s1_w3.png
channel 4 \
1000 ../_data/rxrx1_subset_monai/images/HEPG2-11/Plate2/L21_s2_w4.png
1001 ../_data/rxrx1_subset_monai/images/HEPG2-09/Plate4/I22_s1_w4.png
1002 ../_data/rxrx1_subset_monai/images/HEPG2-10/Plate4/D02_s2_w4.png
1003 ../_data/rxrx1_subset_monai/images/HEPG2-08/Plate1/O05_s1_w4.png
1004 ../_data/rxrx1_subset_monai/images/HEPG2-11/Plate3/M10_s2_w4.png
... ...
1195 ../_data/rxrx1_subset_monai/images/U2OS-05/Plate1/I03_s1_w4.png
1196 ../_data/rxrx1_subset_monai/images/U2OS-05/Plate3/J08_s2_w4.png
1197 ../_data/rxrx1_subset_monai/images/U2OS-04/Plate2/G23_s1_w4.png
1198 ../_data/rxrx1_subset_monai/images/U2OS-04/Plate2/G05_s2_w4.png
1199 ../_data/rxrx1_subset_monai/images/U2OS-05/Plate1/J13_s1_w4.png
channel 5 \
1000 ../_data/rxrx1_subset_monai/images/HEPG2-11/Plate2/L21_s2_w5.png
1001 ../_data/rxrx1_subset_monai/images/HEPG2-09/Plate4/I22_s1_w5.png
1002 ../_data/rxrx1_subset_monai/images/HEPG2-10/Plate4/D02_s2_w5.png
1003 ../_data/rxrx1_subset_monai/images/HEPG2-08/Plate1/O05_s1_w5.png
1004 ../_data/rxrx1_subset_monai/images/HEPG2-11/Plate3/M10_s2_w5.png
... ...
1195 ../_data/rxrx1_subset_monai/images/U2OS-05/Plate1/I03_s1_w5.png
1196 ../_data/rxrx1_subset_monai/images/U2OS-05/Plate3/J08_s2_w5.png
1197 ../_data/rxrx1_subset_monai/images/U2OS-04/Plate2/G23_s1_w5.png
1198 ../_data/rxrx1_subset_monai/images/U2OS-04/Plate2/G05_s2_w5.png
1199 ../_data/rxrx1_subset_monai/images/U2OS-05/Plate1/J13_s1_w5.png
channel 6 label
1000 ../_data/rxrx1_subset_monai/images/HEPG2-11/Plate2/L21_s2_w6.png 0
1001 ../_data/rxrx1_subset_monai/images/HEPG2-09/Plate4/I22_s1_w6.png 0
1002 ../_data/rxrx1_subset_monai/images/HEPG2-10/Plate4/D02_s2_w6.png 0
1003 ../_data/rxrx1_subset_monai/images/HEPG2-08/Plate1/O05_s1_w6.png 0
1004 ../_data/rxrx1_subset_monai/images/HEPG2-11/Plate3/M10_s2_w6.png 0
... ... ...
1195 ../_data/rxrx1_subset_monai/images/U2OS-05/Plate1/I03_s1_w6.png 3
1196 ../_data/rxrx1_subset_monai/images/U2OS-05/Plate3/J08_s2_w6.png 3
1197 ../_data/rxrx1_subset_monai/images/U2OS-04/Plate2/G23_s1_w6.png 3
1198 ../_data/rxrx1_subset_monai/images/U2OS-04/Plate2/G05_s2_w6.png 3
1199 ../_data/rxrx1_subset_monai/images/U2OS-05/Plate1/J13_s1_w6.png 3
[200 rows x 19 columns],
None)Data Augmentation and DataLoader Preparation
In the next cell, we will define the data augmentation techniques and prepare the data loaders for training and validation. Data augmentation is crucial for improving the generalization of our model by artificially increasing the diversity of the training dataset. We will use a combination of intensity scaling, random cropping, rotation, and flipping transformations.
- The
ScaleIntensityRangePercentilestransformation scales the intensity values of the images based on the specified percentiles. - The
RandomResizedCroptransformation randomly crops the images to the specified size with a random scale. - The
RandRot90transformation randomly rotates the images by 90 degrees with the specified probability. - The
RandFliptransformation randomly flips the images horizontally or vertically with the specified probability. - The
BioDataLoaders.createfunction is used to create the data loaders from the CSV file containing the image paths and labels.
- You can adjust the
bsvariable to change the batch size.- Modify the parameters of the transformations to experiment with different augmentation techniques.
- Ensure that the
fn_colandlabel_colparameters match the columns in your CSV file.- Set
show_summarytoTrueto display a summary of the data loaders.
channels = ['channel 1', 'channel 2', 'channel 3', 'channel 4', 'channel 5', 'channel 6']
transforms_train = [
LoadImaged(keys=channels, image_only=True),
EnsureChannelFirstd(keys=channels),
ScaleIntensityRangePercentilesd(
keys=channels, lower=1.0, upper=99.0, b_min=0.0, b_max=1.0, clip=True
),
ConcatItemsd(keys=channels, name="image", dim=0),
EnsureTyped(keys=["image", "label"], track_meta=False),
RandRotate90d(keys=channels, prob=0.75),
RandFlipd(keys=channels, spatial_axis=[0, 1], prob=0.5),
RandZoomd(keys=channels, min_zoom=0.9, max_zoom=1.1, prob=0.5),
]
transforms_val = [
LoadImaged(keys=channels, image_only=True),
EnsureChannelFirstd(keys=channels),
ScaleIntensityRangePercentilesd(
keys=channels, lower=1.0, upper=99.0, b_min=0.0, b_max=1.0, clip=True
),
ConcatItemsd(keys=channels, name="image", dim=0),
]data_ops = {
'x_keys': "image",
'y_keys': "label",
'transforms': transforms_train,
'val_transforms': transforms_val,
'vocab': list(class_map.keys()),
'seed': 42,
'batch_size': 8,
'val_batch_size': 32,
'num_workers': 16,
'show_summary': True,
}
data = BioDataLoaders.create(
data_folder + 'train.csv',
dataset='cache',
**data_ops,
)Loading dataset: 100%|██████████| 889/889 [00:16<00:00, 53.68it/s]
Loading dataset: 100%|██████████| 111/111 [00:01<00:00, 56.02it/s]
Train DataLoader
----------------
Dataset size : 889
Batch size : 8
Batches : 112
Classes : ['HEPG2', 'HUVEC', 'RPE', 'U2OS']
Batch structure:
[0] shape=(8, 6, 512, 512) dtype=torch.float32 ~48.00 MB
[1] shape=(8,) dtype=torch.int64 ~0.00 MB
Approx batch memory: 48.00 MB
Valid DataLoader
----------------
Dataset size : 111
Batch size : 32
Batches : 4
Classes : ['HEPG2', 'HUVEC', 'RPE', 'U2OS']
Batch structure:
[0] shape=(32, 6, 512, 512) dtype=torch.float32 ~192.00 MB
[1] shape=(32,) dtype=torch.int64 ~0.00 MB
Approx batch memory: 192.00 MBVisualize Data Batch
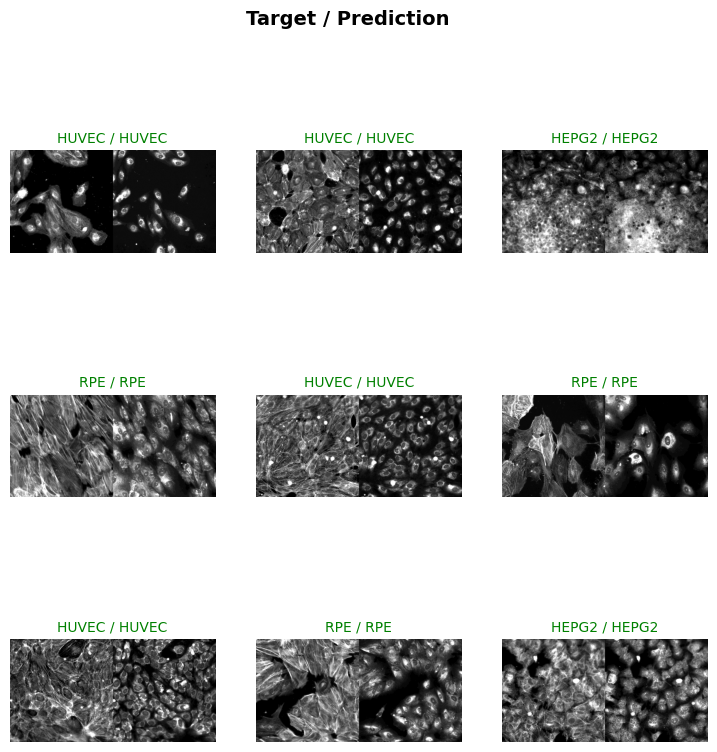
In the next cell, we will visualize a batch of images from the training dataset. This step is essential for verifying that the data augmentation techniques are applied correctly and that the images are loaded as expected. The show_batch method of the BioDataLoaders class is used to display a batch of images with their corresponding labels.
- The
max_slicesparameter specifies the maximum number of slices to display for each image. - The
layoutparameter determines the layout of the displayed images. The ‘multirow’ layout arranges the images in multiple rows.
- You can adjust the
max_slicesparameter to display more or fewer slices per image.- Modify the
layoutparameter to experiment with different layouts, such as ‘single’ or ‘grid’.- Ensure that the data loaders are correctly defined and contain the expected images and labels.
data.show_batch(max_slices=6, layout='multirow')
Visualize a Specific Image
In the next cell, we will visualize a specific image from the dataset using its index. This step is useful for inspecting individual images and verifying their quality and labels. The do_item method of the BioDataLoaders class is used to retrieve the image and its label, and the show method is used to display the image.
from bioMONAI.visualize import mosaic_image_3d
mosaic_image_3d(data.do_item(100)[0])
Define and Train the Model
In the next cell, we will define and train a DenseNet169 model for our multispectral classification task. The model is initialized with the following parameters: - spatial_dims=2: Specifies that the input images are 2D. - in_channels=6: Specifies the number of input channels, which corresponds to the six multispectral channels. - out_channels=data.c: Specifies the number of output channels, which corresponds to the number of classes in our dataset. - pretrained=True: Initializes the model with pretrained weights.
We will also define the metrics to evaluate the model’s performance during training. The RocAuc and accuracy metrics are used to measure the model’s performance.
The fastTrainer class is used to train the model with the specified data loaders and metrics. The fine_tune method is called to fine-tune the model for a specified number of epochs, with an initial phase of freezing the pretrained layers.
- You can experiment with different model architectures by replacing
DenseNet169with other models from themonai.networks.netsmodule.- Adjust the
in_channelsparameter if your dataset contains a different number of channels.- Modify the
out_channelsparameter if your dataset has a different number of classes.- Experiment with different metrics by adding or removing metrics from the
metricslist.- Adjust the number of epochs and the
freeze_epochsparameter to control the training process.
import torch
torch.cuda.empty_cache()
torch.cuda.reset_peak_memory_stats()from monai.networks.nets import DenseNet169
model = DenseNet169(spatial_dims=2, in_channels=6, out_channels=len(data.vocab), pretrained=True)metrics = [accuracy]
optimizer = OptimWrapper(opt=Adam(model.parameters(), 1e-5))
loss_fn=CrossEntropyLossFlat()
trainer = fastTrainer(data, model, loss_fn=loss_fn, metrics=metrics, show_summary=False, lr=1e-5, show_graph=True, optimizer=optimizer)trainer.fit(4)| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.837345 | 0.467119 | 0.945946 | 00:14 |
| 1 | 0.437473 | 0.215604 | 0.972973 | 00:13 |
| 2 | 0.278245 | 0.099553 | 0.981982 | 00:12 |
| 3 | 0.238789 | 0.070104 | 0.981982 | 00:13 |
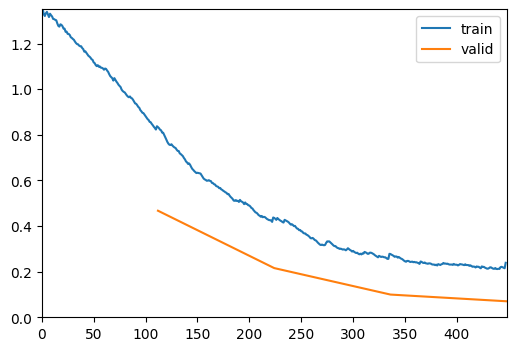
torch.cuda.max_memory_allocated() / 1024**26561.15576171875Save the Trained Model
In the next cell, we will save the trained model to a file. This step is crucial for preserving the model’s state after training, allowing us to load and use the model later without retraining. The save method of the fastTrainer class is used to save the model to the specified file path.
- The
savemethod takes the file name as an argument and saves the model’s state dictionary to a file with the.pthextension. - The saved model can be loaded later using the
loadmethod of thefastTrainerclass.
- You can change the file name to save the model with a different name.
- Ensure that the directory where the model is saved exists and has write permissions.
- Consider saving multiple versions of the model during training to keep track of different checkpoints.
# trainer.save('multispectral-classification-model')Evaluate the Model on Test Data
In the next cell, we will evaluate the trained model on the test dataset. This step is crucial for assessing the model’s performance on unseen data and understanding its generalization capabilities. The BioDataLoaders.class_from_csv function is used to create the data loader for the test dataset, and the evaluate_classification_model function is used to compute the evaluation metrics.
- The
fn_colparameter specifies the columns containing the file paths for the multispectral channels. - The
label_colparameter specifies the column containing the labels. - The
valid_pctparameter is set to 0, indicating that no validation split is needed for the test dataset. - The
item_tfmsparameter applies theScaleIntensityPercentilestransformation to the test images. - The
batch_tfmsparameter applies any batch-level transformations (if defined). - The
bsparameter specifies the batch size for loading the test data. - The
evaluate_classification_modelfunction takes the trained model, test data loader, and evaluation metrics as inputs and returns the computed scores.
- You can adjust the
bsvariable to change the batch size for loading the test data.- Modify the
fn_colandlabel_colparameters to match the columns in your test CSV file.- Add or remove transformations in the
item_tfmsandbatch_tfmslists to experiment with different preprocessing techniques.- Set
show_graphtoTrueto visualize the evaluation results.
test_dl = BioDataLoaders.test_dl(
data_folder + 'test.csv',
dataset='cache',
**data_ops,
)Loading dataset: 100%|██████████| 200/200 [00:03<00:00, 55.22it/s]
Train DataLoader
----------------
Dataset size : 200
Batch size : 8
Batches : 25
Classes : ['HEPG2', 'HUVEC', 'RPE', 'U2OS']
Batch structure:
[0] shape=(8, 6, 512, 512) dtype=torch.float32 ~48.00 MB
[1] shape=(8,) dtype=torch.int64 ~0.00 MB
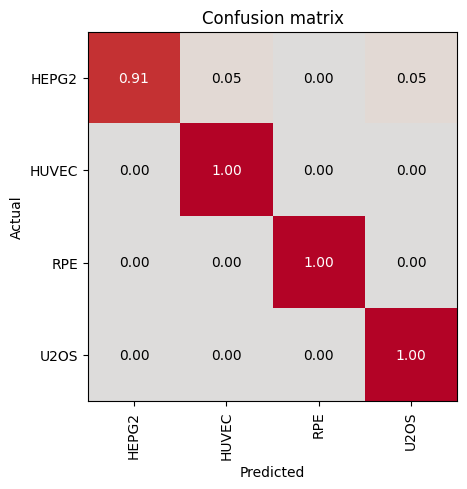
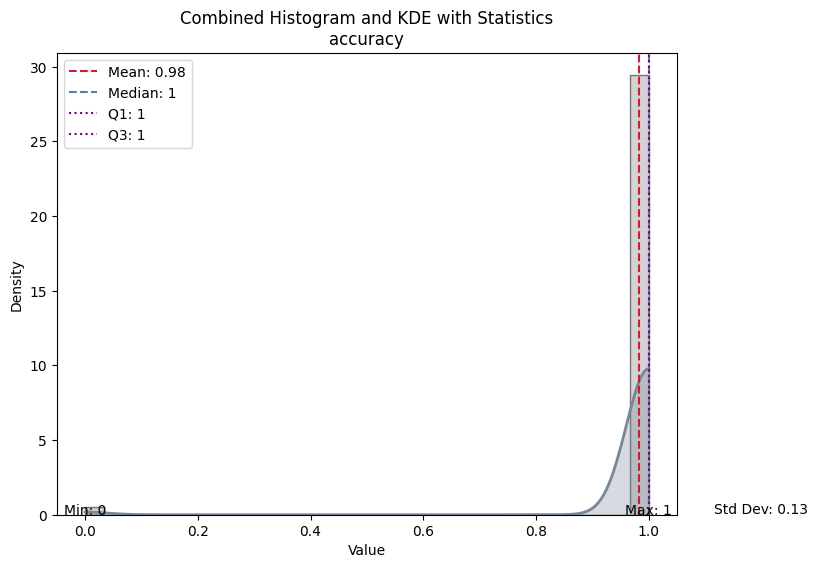
Approx batch memory: 48.00 MBevaluate_classification_model(trainer, test_data=test_dl, metrics=accuracy, show_graph=True, show_results=True); # type:ignore precision recall f1-score support
HEPG2 1.00 0.91 0.95 22
HUVEC 0.97 1.00 0.99 34
RPE 1.00 1.00 1.00 27
U2OS 0.97 1.00 0.98 28
accuracy 0.98 111
macro avg 0.98 0.98 0.98 111
weighted avg 0.98 0.98 0.98 111
Most Confused Classes:| Actual Class | Predicted Class | Count | |
|---|---|---|---|
| 0 | HEPG2 | HUVEC | 1 |
| 1 | HEPG2 | U2OS | 1 |
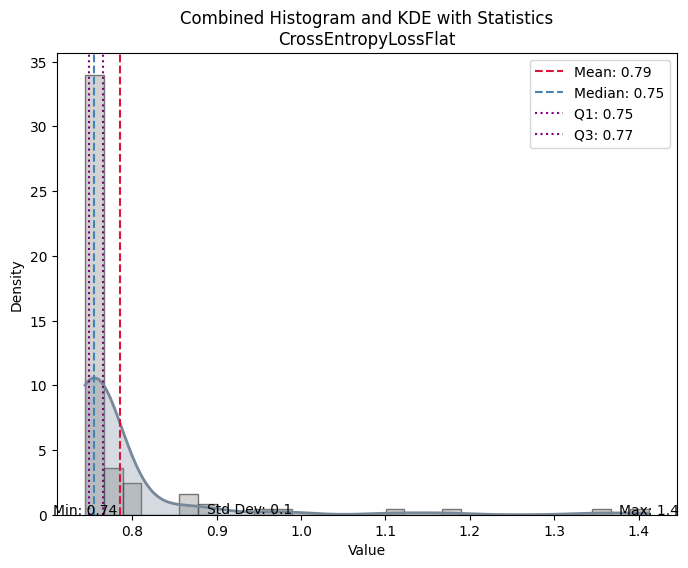
| Value | |
|---|---|
| CrossEntropyLossFlat | |
| Mean | 0.785330 |
| Median | 0.754829 |
| Standard Deviation | 0.103166 |
| Min | 0.744105 |
| Max | 1.411858 |
| Q1 | 0.748401 |
| Q3 | 0.765274 |
| Value | |
|---|---|
| accuracy | |
| Mean | 0.981982 |
| Median | 1.000000 |
| Standard Deviation | 0.133016 |
| Min | 0.000000 |
| Max | 1.000000 |
| Q1 | 1.000000 |
| Q3 | 1.000000 |