from bioMONAI.data import *
from bioMONAI.transforms import *
from bioMONAI.core import *
from bioMONAI.core import Path
from bioMONAI.data import get_image_files
from bioMONAI.losses import *
from bioMONAI.metrics import *
from bioMONAI.datasets import download_medmnist
from fastai.vision.all import CategoryBlock, GrandparentSplitter, parent_label, resnet34, CrossEntropyLossFlat, accuracyImage Classification 2D
Setup imports
device = get_device()
print(device)cudaDataset Information and Download
We’ll employ the publicly available BloodMNIST dataset. The BloodMNIST is based on a dataset of individual normal cells, captured from individuals without infection, hematologic or oncologic disease and free of any pharmacologic treatment at the moment of blood collection. It contains a total of 17,092 images and is organized into 8 classes.
In this step, we will download the BloodMNIST dataset using the
download_medmnistfunction from bioMONAI. This function will download the dataset and provide information about it. The dataset will be stored in the specified path. You can customize the path or dataset name as needed. Additionally, you can explore other datasets available in the MedMNIST collection by changing the dataset name in thedownload_medmnistfunction.
image_path = Path('../_data/medmnist_data/')
info = download_medmnist('bloodmnist', image_path, download_only=True)Dataset 'bloodmnist' is already downloaded and available in '../_data/medmnist_data/bloodmnist'.Create DataLoader
In this step, we will customize the DataLoader for the BloodMNIST dataset. The DataLoader is responsible for loading the data during training and validation. We will define the data loading strategy using the BioDataLoaders.from_source() method, which is is the most general method to deal with various kinds of data and tasks. We will configure the dataloader with the arguments specified in data_ops.
You can customize the following parameters to suit your needs: -
batch_size: The number of samples per batch. Adjust this based on your GPU memory capacity. -item_tfms: List of item-level transformations to apply to the images. You can add or modify transformations to augment your dataset. -splitter: The method to split the dataset into training and validation sets. You can customize the split strategy if needed.Feel free to experiment with different configurations to improve model performance or adapt to different datasets.
batch_size = 32
path = image_path/'bloodmnist'
train_path = path/'train'
val_path = path/'val'
data_ops = {
'blocks': (BioImageBlock(cls=BioImageMulti), CategoryBlock(info['label'])), # define a `TransformBlock` tailored for bioimaging data
'get_items': get_image_files, # get image files in path
'get_y': parent_label, # Label item with the parent folder name
'splitter': GrandparentSplitter(train_name='train', valid_name='val'), # split data with the grandparent folder name
'item_tfms': [ScaleImage(min=0.0, max=1.0), RandRot90(prob=0.75), RandFlip(prob=0.75)], # list of item transforms
'bs': batch_size, # batch size
}
data = BioDataLoaders.from_source(
path, # root directory for data
show_summary=False, # print summary of the data
**data_ops, # rest of method arguments
)
# print length of training and validation datasets
print('train images:', len(data.train_ds.items), '\nvalidation images:', len(data.valid_ds.items))train images: 11959
validation images: 1712Visualize a Batch of Images
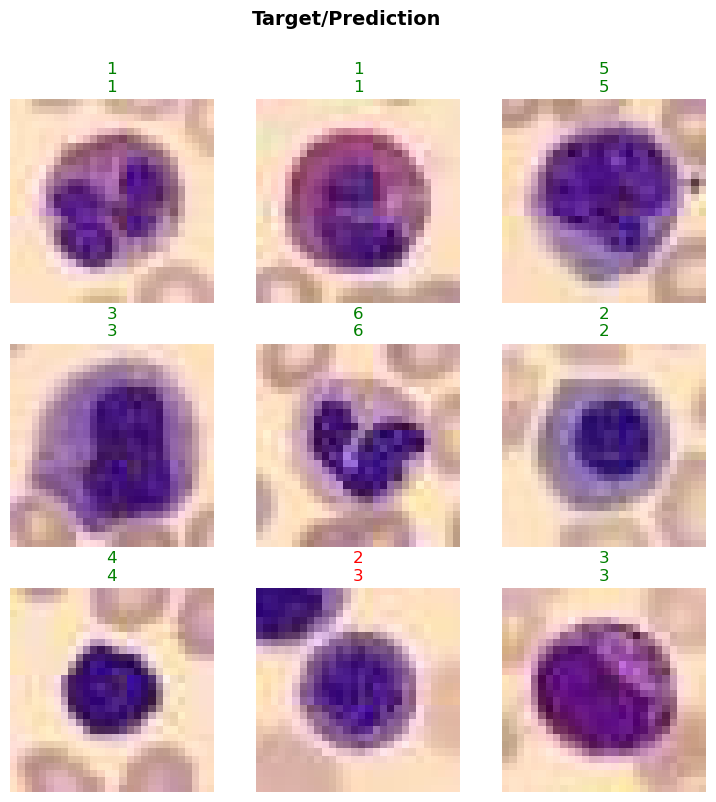
In this step, we will visualize a batch of images from the BloodMNIST dataset using the show_batch method. This will help us understand the data distribution and verify the transformations applied to the images. The max_n parameter specifies the number of images to display.
- You can adjust the
max_nparameter to display more or fewer images.- Experiment with different transformations in the
item_tfmslist to see their effects on the images.- Use the
show_batchmethod at different stages of your data pipeline to ensure the data is being processed correctly.
data.show_batch(max_n=4)
Train the Model
In this step, we will train the model using the visionTrainer class. The fine_tune method will be used to fine-tune the model for a specified number of epochs. The freeze_epochs parameter allows you to freeze the initial layers of the model for a certain number of epochs before unfreezing and training the entire model.
- You can adjust the
epochsparameter to train the model for more or fewer epochs based on your dataset and computational resources.- Experiment with different values for
freeze_epochsto see how it affects model performance.- Monitor the training process and adjust the learning rate or other hyperparameters if needed.
- Consider using techniques like early stopping or learning rate scheduling to improve training efficiency and performance.
VisionTrainer Class
The visionTrainer class is a high-level API designed to simplify the training process for vision models. It provides a convenient interface for training, fine-tuning, and evaluating deep learning models. Here are some key features and functionalities of the visionTrainer class:
- Initialization: The class is initialized with the data, model architecture, loss function, and metrics. It also provides options to display a summary of the model and data.
- Fine-tuning: The
fine_tunemethod allows you to fine-tune the model for a specified number of epochs. You can freeze the initial layers of the model for a certain number of epochs before unfreezing and training the entire model. - Training: The class handles the training loop, including forward and backward passes, loss computation, and optimization.
- Evaluation: The class provides methods to evaluate the model on validation and test datasets, compute metrics, and visualize results.
- Customization: You can customize various aspects of the training process, such as learning rate, batch size, and data augmentations, to suit your specific needs.
The
visionTrainerclass is designed to streamline the training process, making it easier to experiment with different models and hyperparameters. It is particularly useful for tasks like image classification, where you can leverage pre-trained models and fine-tune them on your dataset.
model = resnet34
loss = CrossEntropyLossFlat()
metrics = accuracy
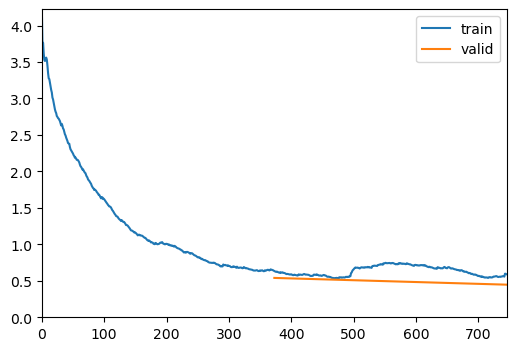
trainer = visionTrainer(data, model, loss_fn=loss, metrics=metrics, show_summary=False)Downloading: "https://download.pytorch.org/models/resnet34-b627a593.pth" to /home/biagio/.cache/torch/hub/checkpoints/resnet34-b627a593.pth100%|██████████| 83.3M/83.3M [00:07<00:00, 11.4MB/s] trainer.fine_tune(10, freeze_epochs=2)| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.656182 | 0.390049 | 0.851051 | 00:20 |
| 1 | 0.714228 | 0.529128 | 0.808995 | 00:20 |
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.360797 | 0.253240 | 0.912967 | 00:21 |
| 1 | 0.334948 | 0.415015 | 0.858645 | 00:20 |
| 2 | 0.380405 | 0.310013 | 0.895444 | 00:21 |
| 3 | 0.302011 | 0.310726 | 0.891939 | 00:23 |
| 4 | 0.246056 | 0.198853 | 0.923481 | 00:22 |
| 5 | 0.191048 | 0.159629 | 0.939252 | 00:23 |
| 6 | 0.137073 | 0.176325 | 0.945678 | 00:23 |
| 7 | 0.114239 | 0.122808 | 0.959112 | 00:22 |
| 8 | 0.088355 | 0.119864 | 0.960280 | 00:23 |
| 9 | 0.080972 | 0.107884 | 0.967290 | 00:23 |
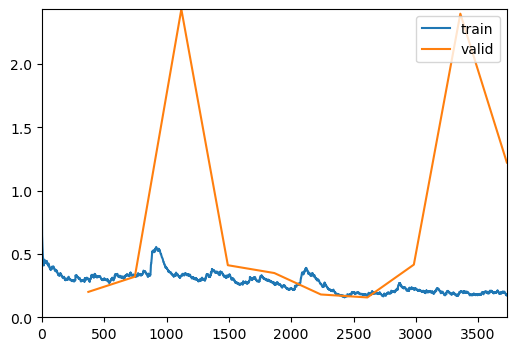
Evaluate the Model on Validation Data
In this step, we will evaluate the trained model on the validation dataset using the evaluate_classification_model function. This function computes the specified metrics and provides insights into the model’s performance. Additionally, it can display the most confused classes to help identify areas for improvement.
- You can customize the
metricsparameter to include other evaluation metrics relevant to your task.- The
most_confused_nparameter specifies the number of most confused classes to display. Adjust this value to see more or fewer confused classes.- Set the
show_graphparameter toTrueto visualize the confusion matrix and other evaluation graphs.- Use this evaluation step to monitor the model’s performance and make necessary adjustments to the training process or data pipeline.
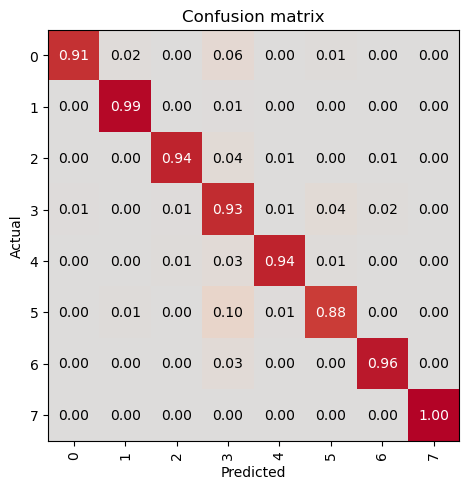
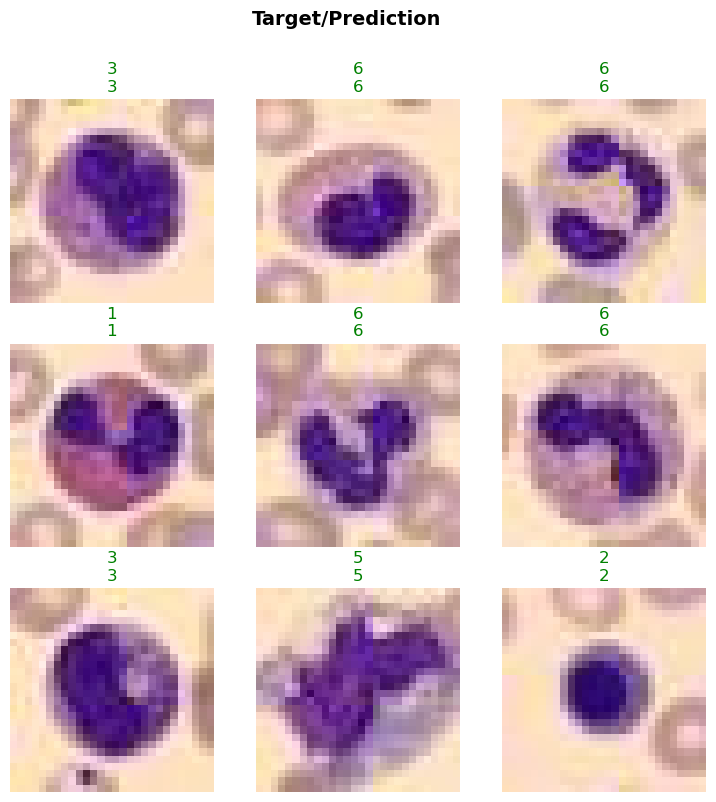
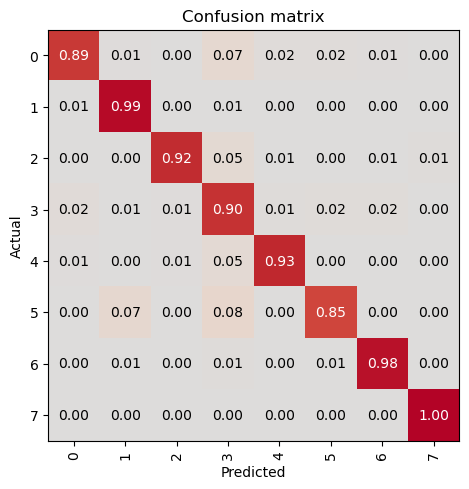
evaluate_classification_model(trainer, metrics=metrics, most_confused_n=5, show_graph=False); precision recall f1-score support
0 0.91 0.96 0.94 122
1 0.99 0.99 0.99 312
2 0.99 0.96 0.97 155
3 0.92 0.89 0.90 290
4 0.94 0.96 0.95 122
5 0.91 0.91 0.91 143
6 0.98 0.98 0.98 333
7 1.00 1.00 1.00 235
accuracy 0.96 1712
macro avg 0.95 0.96 0.96 1712
weighted avg 0.96 0.96 0.96 1712
Most Confused Classes:[('5', '3', np.int64(9)), ('3', '0', np.int64(8)), ('3', '5', np.int64(8)), ('3', '6', np.int64(7)), ('4', '3', np.int64(6))]| Value | |
|---|---|
| CrossEntropyLossFlat | |
| Mean | 1.322254 |
| Median | 1.274700 |
| Standard Deviation | 0.158097 |
| Min | 1.274009 |
| Max | 2.273924 |
| Q1 | 1.274134 |
| Q3 | 1.281225 |
| Value | |
|---|---|
| accuracy | |
| Mean | 0.965537 |
| Median | 1.000000 |
| Standard Deviation | 0.182414 |
| Min | 0.000000 |
| Max | 1.000000 |
| Q1 | 1.000000 |
| Q3 | 1.000000 |
Save the Model
In this step, we will save the trained model using the save method of the visionTrainer class. Saving the model allows us to reuse it later without retraining. This is particularly useful when you want to deploy the model or continue training at a later time.
- You can specify the file path and name for the saved model. Ensure the directory exists or create it if necessary.
- Consider saving the model at different checkpoints during training to have backups and the ability to revert to a previous state if needed.
- You can also save additional information such as the training history, optimizer state, and hyperparameters to facilitate future use or further training.
trainer.save('tmp-model')Path('models/tmp-model.pth')Evaluate the Model on Test Data
In this step, we will evaluate the trained model on the test dataset to assess its performance on unseen data. This is a crucial step to ensure that the model generalizes well and performs accurately on new, unseen samples. We will use the evaluate_classification_model function to compute the specified metrics and gain insights into the model’s performance.
- Ensure that the test dataset is completely separate from the training and validation datasets to get an unbiased evaluation.
- You can customize the
metricsparameter to include other evaluation metrics relevant to your task.- The
show_graphparameter can be set toTrueto visualize the confusion matrix and other evaluation graphs.- Use this evaluation step to identify any potential issues with the model and make necessary adjustments to the training process or data pipeline.
- Consider experimenting with different model architectures, hyperparameters, and data augmentations to further improve performance.
test_path = path/'test'
test_data = data.test_dl(get_image_files(test_path).shuffle(), with_labels=True)
# print length of test dataset
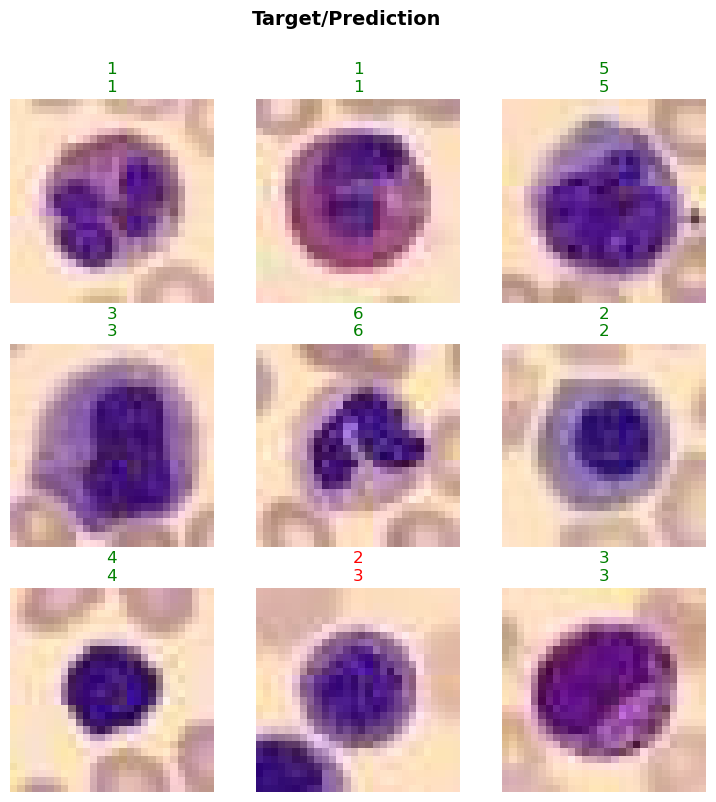
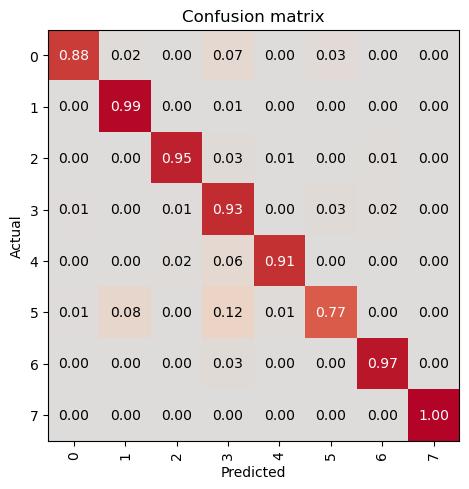
print('test images:', len(test_data.items))test images: 3421evaluate_classification_model(trainer, test_data, metrics=metrics, show_graph=False); precision recall f1-score support
0 0.95 0.95 0.95 244
1 0.99 0.99 0.99 624
2 0.99 0.95 0.97 311
3 0.89 0.92 0.91 579
4 0.93 0.97 0.95 243
5 0.94 0.88 0.91 284
6 0.97 0.97 0.97 666
7 1.00 1.00 1.00 470
accuracy 0.96 3421
macro avg 0.96 0.95 0.96 3421
weighted avg 0.96 0.96 0.96 3421
Most Confused Classes:[('5', '3', np.int64(31)), ('3', '5', np.int64(17)), ('3', '6', np.int64(16)), ('6', '3', np.int64(14)), ('2', '3', np.int64(9)), ('4', '3', np.int64(9)), ('3', '0', np.int64(7)), ('3', '4', np.int64(7)), ('5', '4', np.int64(7)), ('0', '3', np.int64(6)), ('0', '4', np.int64(3)), ('0', '5', np.int64(3)), ('2', '6', np.int64(3)), ('3', '2', np.int64(3)), ('1', '3', np.int64(2)), ('2', '0', np.int64(2)), ('2', '4', np.int64(2)), ('0', '1', np.int64(1)), ('1', '0', np.int64(1)), ('1', '5', np.int64(1)), ('2', '1', np.int64(1)), ('3', '1', np.int64(1)), ('4', '0', np.int64(1)), ('5', '0', np.int64(1)), ('5', '6', np.int64(1)), ('6', '0', np.int64(1)), ('6', '1', np.int64(1)), ('6', '2', np.int64(1)), ('7', '2', np.int64(1))]| Value | |
|---|---|
| CrossEntropyLossFlat | |
| Mean | 1.326528 |
| Median | 1.274774 |
| Standard Deviation | 0.167805 |
| Min | 1.274009 |
| Max | 2.274008 |
| Q1 | 1.274136 |
| Q3 | 1.283284 |
| Value | |
|---|---|
| accuracy | |
| Mean | 0.957322 |
| Median | 1.000000 |
| Standard Deviation | 0.202129 |
| Min | 0.000000 |
| Max | 1.000000 |
| Q1 | 1.000000 |
| Q3 | 1.000000 |
Load the Model
In this step, we will load the previously trained model using the load method of the visionTrainer class. In this example, we will:
- Create a trainer instance and load the previously saved model.
- Train the model a several epochs more.
- Evaluate the model with test data again.
model = resnet34
loss = CrossEntropyLossFlat()
metrics = accuracy
trainer2 = visionTrainer(data, model, loss_fn=loss, metrics=metrics, show_summary=False)
# Load saved model
trainer2.load('tmp-model')
# Train several additional epochs
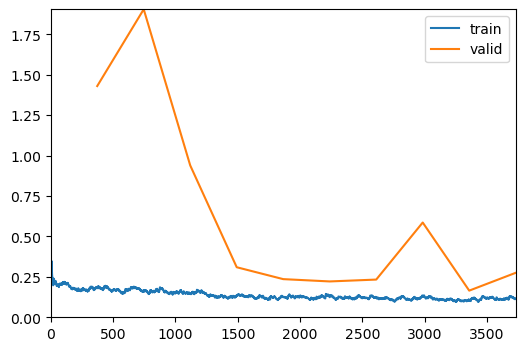
trainer2.fit_one_cycle(10, lr_max=5e-5)
# Evaluate the model on the test dataset
evaluate_classification_model(trainer2, test_data, metrics=metrics, show_graph=False);| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.073839 | 0.111159 | 0.960864 | 00:23 |
| 1 | 0.072782 | 0.115031 | 0.963785 | 00:22 |
| 2 | 0.083870 | 0.118928 | 0.959696 | 00:23 |
| 3 | 0.081045 | 0.118906 | 0.957360 | 00:24 |
| 4 | 0.081342 | 0.111984 | 0.964369 | 00:23 |
| 5 | 0.078157 | 0.117275 | 0.960864 | 00:22 |
| 6 | 0.065040 | 0.113551 | 0.966121 | 00:23 |
| 7 | 0.074214 | 0.106381 | 0.969042 | 00:23 |
| 8 | 0.078575 | 0.116092 | 0.963785 | 00:23 |
| 9 | 0.053099 | 0.110363 | 0.962033 | 00:23 |
precision recall f1-score support
0 0.96 0.94 0.95 244
1 0.99 0.99 0.99 624
2 0.97 0.96 0.96 311
3 0.91 0.91 0.91 579
4 0.94 0.96 0.95 243
5 0.90 0.92 0.91 284
6 0.97 0.97 0.97 666
7 1.00 1.00 1.00 470
accuracy 0.96 3421
macro avg 0.96 0.96 0.96 3421
weighted avg 0.96 0.96 0.96 3421
Most Confused Classes:[('3', '5', np.int64(22)), ('3', '6', np.int64(16)), ('6', '3', np.int64(13)), ('5', '3', np.int64(12)), ('0', '3', np.int64(9)), ('2', '3', np.int64(8)), ('4', '3', np.int64(8)), ('0', '5', np.int64(6)), ('5', '4', np.int64(5)), ('3', '4', np.int64(4)), ('3', '0', np.int64(3)), ('3', '2', np.int64(3)), ('0', '4', np.int64(2)), ('1', '3', np.int64(2)), ('2', '6', np.int64(2)), ('1', '0', np.int64(1)), ('1', '5', np.int64(1)), ('1', '6', np.int64(1)), ('2', '0', np.int64(1)), ('2', '1', np.int64(1)), ('2', '5', np.int64(1)), ('3', '1', np.int64(1)), ('4', '0', np.int64(1)), ('4', '2', np.int64(1)), ('4', '5', np.int64(1)), ('5', '0', np.int64(1)), ('5', '6', np.int64(1)), ('6', '0', np.int64(1)), ('6', '1', np.int64(1)), ('6', '2', np.int64(1)), ('7', '2', np.int64(1))]| Value | |
|---|---|
| CrossEntropyLossFlat | |
| Mean | 1.322993 |
| Median | 1.274470 |
| Standard Deviation | 0.166732 |
| Min | 1.274009 |
| Max | 2.274009 |
| Q1 | 1.274075 |
| Q3 | 1.279562 |
| Value | |
|---|---|
| accuracy | |
| Mean | 0.961999 |
| Median | 1.000000 |
| Standard Deviation | 0.191198 |
| Min | 0.000000 |
| Max | 1.000000 |
| Q1 | 1.000000 |
| Q3 | 1.000000 |